|
Giới thiệu về Decompilation vs. Disassembly
Trình dịch ngược “Decompiler” thể hiện các tệp nhị phân thực thi “Executable binary files” ở dạng có thể đọc được. Chính xác hơn, nó chuyển đổi mã nhị phân thành văn bản mà các nhà phát triển phần mềm có thể đọc và sửa đổi. Ngành bảo mật phần mềm dựa vào sự chuyển đổi này để phân tích và xác thực các chương trình. Việc phân tích được thực hiện trên mã nhị phân vì mã nguồn “source code ” (dạng văn bản của phần mềm) theo truyền thống không có sẵn vì nó được coi là bí mật thương mại.
Các chương trình chuyển đổi mã nhị phân thành dạng văn bản luôn tồn tại. Việc ánh xạ một-một đơn giản các mã lệnh của bộ xử lý vào trong việc ghi nhớ lệnh được thực hiện bởi các trình tháo gỡ hay trình phân tách “Disassemblers”. Có rất nhiều công cụ tháo gỡ có sẵn trên thị trường, cả miễn phí và thương mại. Trình dịch ngược mạnh mẽ nhất là IDA Pro của Hex-Rays. Nó có thể xử lý mã nhị phân cho một số lượng lớn bộ xử lý và có kiến trúc mở cho phép các nhà phát triển viết các mô-đun phân tích bổ sung.
Trình dịch ngược “Decompiler” khác với trình tháo gỡ “Disassemblers” ở một khía cạnh rất quan trọng. Mặc dù cả hai đều tạo ra văn bản mà con người có thể đọc được, nhưng Trình dịch ngược “Decompiler” lại tạo ra văn bản cấp cao hơn nhiều, ngắn gọn hơn và dễ đọc hơn nhiều.
So với ngôn ngữ hợp ngữ cấp thấp, biểu diễn ngôn ngữ cấp cao có một số ưu điểm:
-
Đó là sự đồng ý.
-
Nó có cấu trúc.
-
Nó không yêu cầu các nhà phát triển phải biết ngôn ngữ lập trình Assembly Language.
-
Nó nhận biết và chuyển đổi các thành ngữ cấp thấp “Low level idioms” thành các khái niệm cấp cao “High Level notions”.
-
Nó ít gây nhầm lẫn hơn và do đó dễ hiểu hơn.
-
Nó ít lặp đi lặp lại và ít gây mất tập trung hơn.
-
Nó sử dụng phân tích luồng dữ liệu “Data Flow Analysis”.
Chúng ta hãy xem xét những điểm này một cách chi tiết.
Thông thường, đầu ra của trình dịch ngược “Decompiler” ngắn hơn năm đến mười lần so với đầu ra của trình tháo gỡ “Disassemblers”. Ví dụ: một chương trình hiện đại điển hình chứa từ 400KB đến 5 MB mã nhị phân. Đầu ra của trình tháo gỡ “Disassemblers” cho một chương trình như vậy sẽ bao gồm khoảng 5-100MB văn bản, có thể mất từ vài tuần đến vài tháng để phân tích hoàn toàn. Các nhà phân tích không thể dành nhiều thời gian như vậy cho một chương trình vì lý do kinh tế.
Đầu ra của trình dịch ngược “Decompiler” cho một chương trình thông thường sẽ từ 400KB đến 10MB. Mặc dù đây vẫn là một khối lượng lớn để đọc và hiểu (có kích thước bằng một cuốn sách dày) nhưng thời gian cần thiết cho thời gian phân tích được chia cho 10 trở lên.
Sự khác biệt lớn thứ hai là đầu ra của trình dịch ngược “Decompiler” có cấu trúc. Thay vì một luồng hướng dẫn tuyến tính trong đó mỗi dòng tương tự với tất cả các dòng khác, văn bản được thụt vào để làm cho logic chương trình trở nên rõ ràng. Các cấu trúc luồng điều khiển như câu lệnh điều kiện, vòng lặp và công tắc được đánh dấu bằng các từ khóa thích hợp.
Đầu ra của trình dịch ngược “Decompiler” dễ hiểu hơn đầu ra của trình tháo gỡ “Disassemblers” vì nó ở mức cao. Để có thể sử dụng trình tháo gỡ “Disassemblers”, nhà phân tích phải biết ngôn ngữ hợp ngữ của bộ xử lý đích. Các lập trình viên chính thống không sử dụng hợp ngữ cho các công việc hàng ngày, nhưng ngày nay hầu như mọi người đều sử dụng ngôn ngữ cấp cao. Trình dịch ngược “Decompiler” loại bỏ khoảng cách giữa ngôn ngữ lập trình điển hình và ngôn ngữ đầu ra. Nhiều nhà phân tích có thể sử dụng trình giải mã hơn là trình dịch ngược.
Trình dịch ngược “Decompiler” chuyển đổi các thành ngữ ở mức hợp ngữ thành các thành phần trừu tượng ở mức cao. Một số thành ngữ có thể khá dài và tốn thời gian để phân tích. Mã một dòng sau đây
x = y / 2;
có thể được trình biên dịch “Compiler” chuyển đổi thành một chuỗi gồm 20-30 lệnh xử lý “Processor Instructions”. Phải mất ít nhất 15-30 giây để một nhà phân tích có kinh nghiệm nhận ra mẫu “pattern” và thay thế nó bằng dòng lệnh “line” ban đầu trong đầu. Nếu mã bao gồm nhiều thành ngữ như vậy, nhà phân tích buộc phải ghi chú và đánh dấu từng mẫu bằng cách trình bày ngắn gọn của nó. Tất cả điều này làm chậm quá trình phân tích rất nhiều. Trình dịch ngược “Decompiler” loại bỏ gánh nặng này khỏi các nhà phân tích.
Số lượng lệnh Assembler instructions để phân tích là rất lớn. Chúng trông rất giống nhau và hoa văn của chúng hay lặp đi lặp lại. Đọc kết quả của trình tháo gỡ “Disassemblers” không giống như đọc một câu chuyện hấp dẫn. Trong một chương trình do trình biên dịch “Compiler” tạo ra, 95% mã sẽ thực sự nhàm chán khi đọc và phân tích. Nhà phân tích rất dễ nhầm lẫn giữa hai đoạn mã trông giống nhau và đơn giản là không hiểu được kết quả đầu ra. Hai yếu tố này (kích thước và tính chất nhàm chán của văn bản) dẫn đến hiện tượng sau: chương trình nhị phân không bao giờ được phân tích đầy đủ. Các nhà phân tích cố gắng xác định vị trí các phần đáng ngờ bằng cách sử dụng một số phương pháp phỏng đoán và một số công cụ tự động hóa. Các trường hợp ngoại lệ xảy ra khi chương trình cực kỳ nhỏ hoặc nhà phân tích dành một lượng thời gian rất lớn cho việc phân tích. Trình dịch ngược “Decompiler” giải quyết được cả hai vấn đề: đầu ra của chúng ngắn hơn và ít lặp lại hơn. Đầu ra vẫn chứa một số sự lặp lại, nhưng con người có thể quản lý được. Ngoài ra, sự lặp lại này có thể được giải quyết bằng cách tự động hóa việc phân tích.
Các mẫu “pattern” lặp đi lặp lại trong mã nhị phân cần có giải pháp. Một giải pháp rõ ràng là sử dụng máy tính để tìm ra các mẫu “pattern” và bằng cách nào đó rút gọn chúng thành một cái gì đó ngắn hơn và dễ dàng hơn cho các nhà phân tích con người nắm bắt. Một số trình tháo gỡ (bao gồm IDA Pro) cung cấp phương tiện để tự động phân tích. Tuy nhiên, số lượng mô-đun phân tích có sẵn vẫn ở mức thấp nên mã lặp lại tiếp tục là một vấn đề. Lý do chính là việc nhận dạng các mẫu nhị phân “Binary patterns” là một nhiệm vụ khó khăn một cách đáng ngạc nhiên. Bất kỳ hành động "đơn giản" nào, bao gồm các phép tính số học cơ bản như cộng và trừ, đều có thể được biểu diễn theo vô số cách dưới dạng nhị phân. Trình biên dịch “Compiler” có thể sử dụng toán tử cộng để trừ và ngược lại. Nó có thể lưu trữ các số không đổi ở đâu đó trong bộ nhớ và tải chúng khi cần. Nó có thể sử dụng thực tế là, sau một số thao tác, giá trị thanh ghi có thể được chứng minh là một hằng số đã biết và chỉ sử dụng thanh ghi mà không cần khởi tạo lại nó. Sự đa dạng của các phương pháp được sử dụng giải thích số lượng nhỏ các mô-đun phân tích có sẵn.
Tình hình sẽ khác với trình dịch ngược “Decompiler”. Tự động hóa trở nên dễ dàng hơn nhiều vì trình dịch ngược “Decompiler” cung cấp cho người phân tích các khái niệm cấp cao. Nhiều mẫu được tự động nhận dạng và thay thế bằng các khái niệm trừu tượng. Các mẫu còn lại có thể được phát hiện dễ dàng nhờ các hình thức mà trình dịch ngược “Decompiler” đưa vào. Ví dụ, các khái niệm về tham số hàm và quy ước gọi hàm được chính thức hóa chặt chẽ. Trình dịch ngược “Decompiler” giúp dễ dàng tìm thấy các tham số của bất kỳ lệnh gọi hàm nào, ngay cả khi các tham số đó được khởi tạo cách xa lệnh gọi. Với một trình tháo gỡ “Disassemblers”, đây là một nhiệm vụ khó khăn, đòi hỏi phải xử lý từng trường hợp riêng lẻ.
BTrình dịch ngược “Decompiler”, trái ngược với trình tháo gỡ “Disassemblers”, thực hiện phân tích luồng dữ liệu mở rộng trên đầu vào. Điều này có nghĩa là những câu hỏi như "Biến được khởi tạo ở đâu?" và "Biến này có được sử dụng không?" có thể được trả lời ngay lập tức mà không cần thực hiện bất kỳ tìm kiếm rộng rãi nào về hàm. Các nhà phân tích thường xuyên đặt ra và trả lời những câu hỏi này và có câu trả lời ngay lập tức làm tăng năng suất của họ.
So sánh song song giữa quá trình tháo gỡ và dịch ngược
Dưới đây bạn sẽ tìm thấy những so sánh song song giữa kết quả đầu ra của quá trình tháo gỡ và dịch ngược. Các ví dụ sau đây có sẵn:
Các ví dụ sau đây được trình bày dưới đây:
-
Phép chia cho 2
-
Đơn giản chưa?
-
Biến của tôi ở đâu?
-
Số học không phải là môn khoa học tên lửa
-
Thủ tục Window mẫu
-
Đánh giá ngắn mạch
-
Hoạt động chuỗi nội tuyến
|
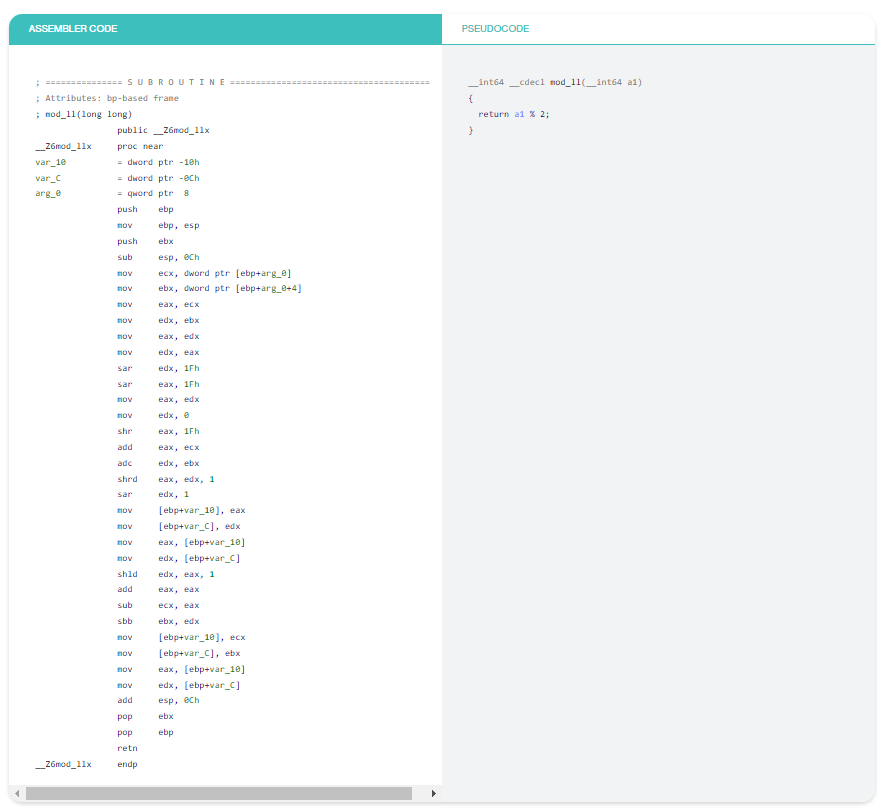
Ví dụ 1: Phép chia cho 2
Chỉ cần lưu ý sự khác biệt về kích thước! Mặc dù đầu ra của quá trình tháo rời “disassemble” yêu cầu bạn không chỉ biết rằng trình biên dịch tạo ra mã phức tạp như vậy cho phép chia có dấu và phép toán modulo, mà bạn còn phải dành thời gian để nhận dạng các mẫu “patterns”. Không cần phải nói, trình dịch ngược “decompiler” khiến mọi việc trở nên thực sự đơn giản.
|
|
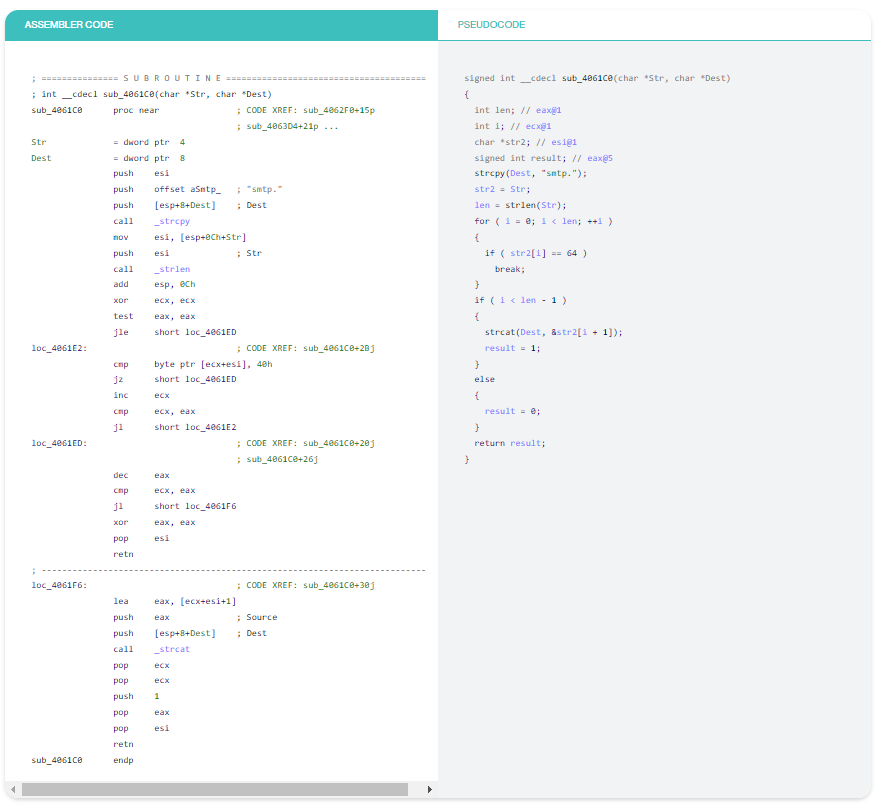
Ví dụ 2: Đơn giản chưa?
Những câu hỏi như
-
Các giá trị trả về có thể có của hàm là gì?
-
Hàm này có sử dụng chuỗi nào không?
-
Hàm này làm gì?
có thể được trả lời gần như ngay lập tức khi nhìn vào đầu ra của trình dịch ngược “decompiler”. Không cần phải nói rằng nó trông đẹp hơn vì tôi đã đổi tên các biến cục bộ. Trong trình tháo gỡ “Disassemblers”, các thanh ghi rất hiếm khi được đổi tên vì nó che giấu việc sử dụng thanh ghi và có thể dẫn đến nhầm lẫn.
|
|
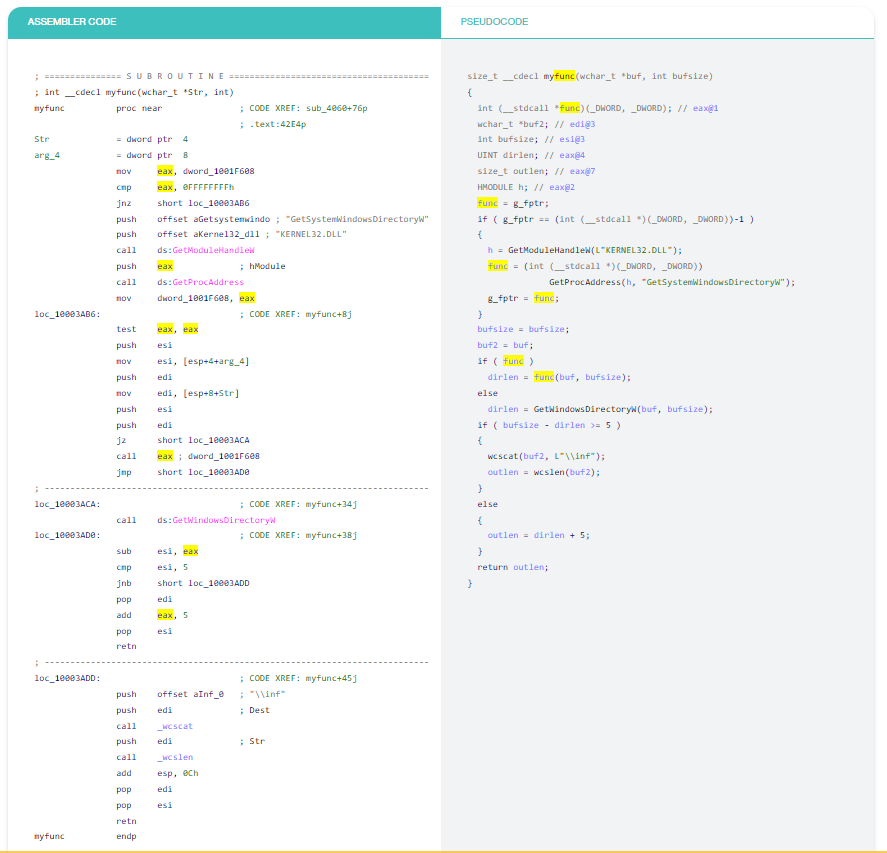
Ví dụ 3: Biến của tôi ở đâu?
IDA đánh dấu mã định danh hiện tại “Current Identifier”. Tính năng này hóa ra hữu ích hơn nhiều với đầu ra ở mức cao. Trong ví dụ này, tôi đã cố gắng theo dõi cách hàm sử dụng con trỏ hàm được truy xuất. Trong đầu ra của quá trình tháo gỡ “Disassembly”, nhiều lần xuất hiện sai wrong eax được đánh dấu trong khi trình dịch ngược “decompiler” thực hiện chính xác những gì tôi muốn.
|
|
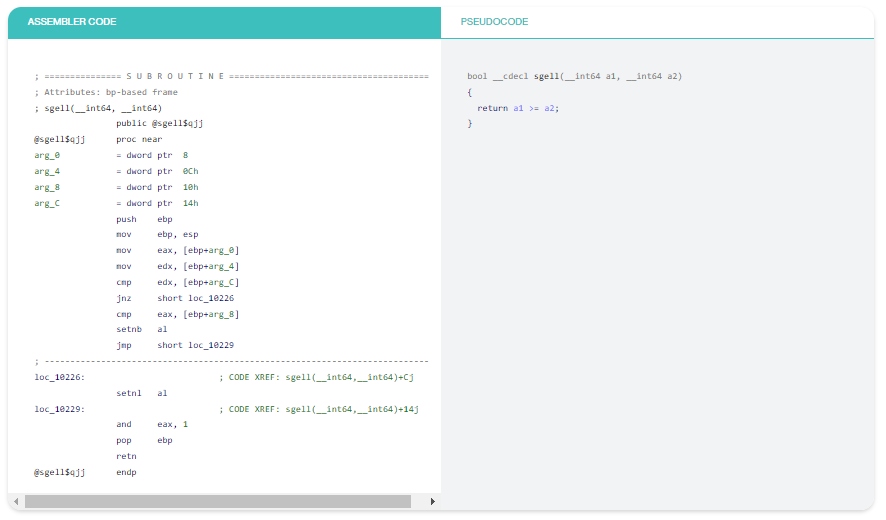
Ví dụ 4: Số học không phải là môn khoa học tên lửa
Số học không phải là một môn khoa học tên lửa nhưng sẽ tốt hơn nếu có ai đó giải quyết nó cho bạn. Bạn có nhiều điều quan trọng hơn để tập trung vào.
|
|
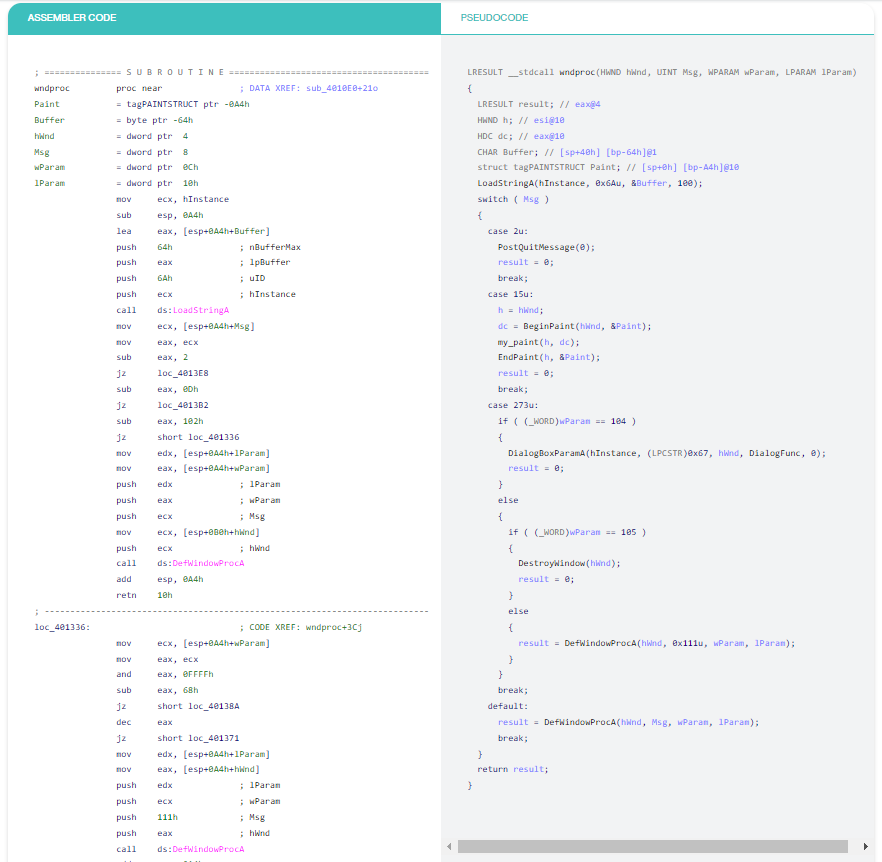
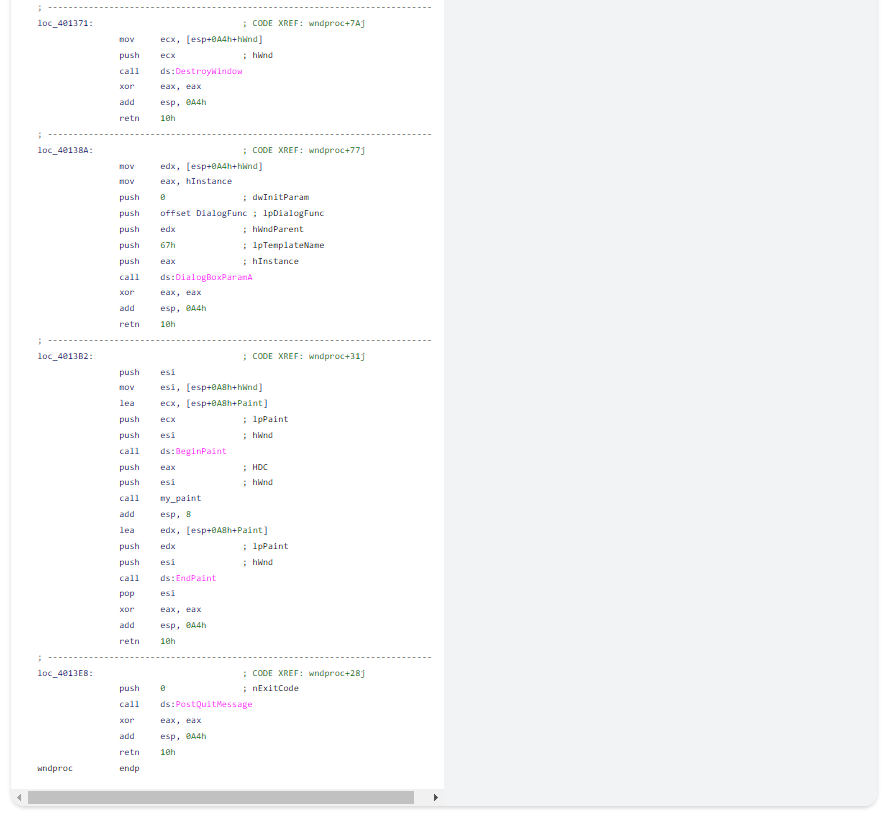
Ví dụ 5: Thủ tục window procedure mẫu
Trình dịch ngược “Decompiler” đã nhận ra câu lệnh switch và thể hiện rõ ràng thủ tục windows procedure. Nếu không có sự trợ giúp nhỏ này, người dùng sẽ phải tự mình tính toán số lượng tin nhắn. Không có gì đặc biệt khó khăn, chỉ tốn thời gian và nhàm chán. Lỡ như cô ấy mắc lỗi thì sao?...
|
|
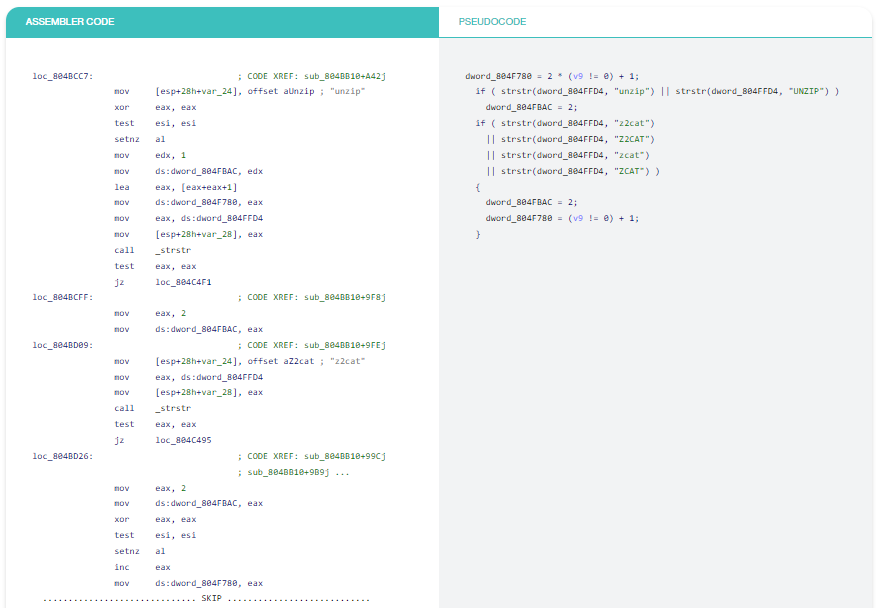
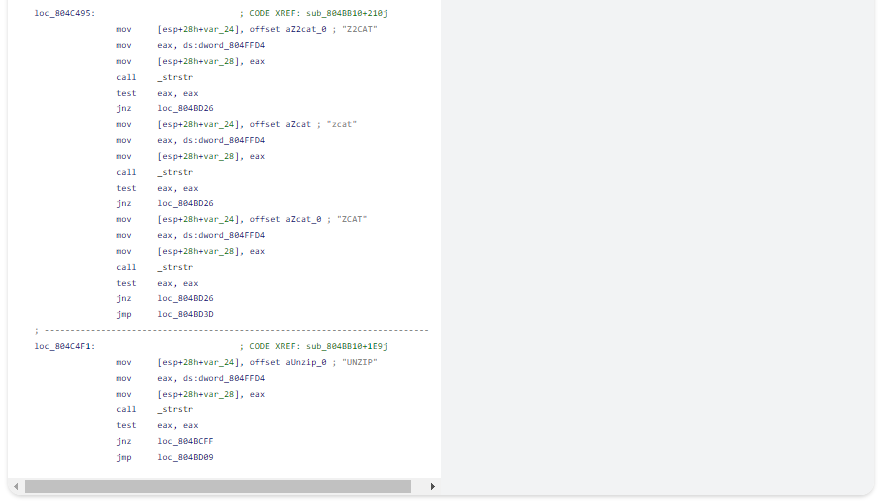
Ví dụ 6: Đánh giá ngắn mạch
Đây là một đoạn trích từ một hàm lớn để minh họa việc đánh giá ngắn mạch. Những điều phức tạp xảy ra trong các hàm dài và sẽ rất tiện lợi khi có trình dịch ngược “Decompiler” để thể hiện mọi thứ theo cách của con người. Xin lưu ý cách mã nằm rải rác trong không gian địa chỉ được hiển thị chính xác trong hai câu lệnh if.
|
|
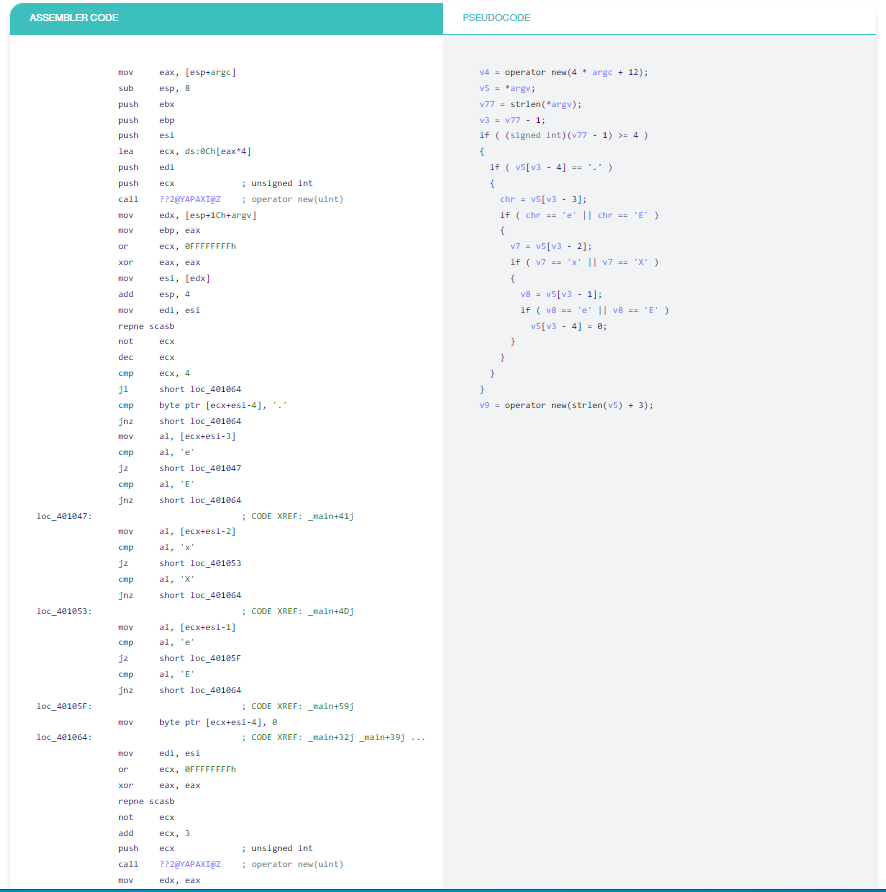
Ví dụ 7: Hoạt động chuỗi nội tuyến
Trình dịch ngược “Decompiler” cố gắng nhận dạng các hàm chuỗi nội tuyến thường xuyên như strcmp, strchr, strlen, v.v. Trong đoạn mã này, các lệnh gọi hàm strlen đã được nhận dạng.
|
|